
Profile

|
Dr. Dominik Rausch |
Publications
Fluid Sketching — Immersive Sketching Based on Fluid Flow

Fluid artwork refers to works of art based on the aesthetics of fluid motion, such as smoke photography, ink injection into water, and paper marbling. Inspired by such types of art, we created Fluid Sketching as a novel medium for creating 3D fluid artwork in immersive virtual environments. It allows artists to draw 3D fluid-like sketches and manipulate them via six degrees of freedom input devices. Different sets of brush strokes are available, varying different characteristics of the fluid. Because of fluid's nature, the diffusion of the drawn fluid sketch is animated, and artists have control over altering the fluid properties and stopping the diffusion process whenever they are satisfied with the current result. Furthermore, they can shape the drawn sketch by directly interacting with it, either with their hand or by blowing into the fluid. We rely on particle advection via curl-noise as a fast procedural method for animating the fluid flow.
» Show BibTeX
@InProceedings{Eroglu2018,
author = {Eroglu, Sevinc and Gebhardt, Sascha and Schmitz, Patric and Rausch, Dominik and Kuhlen, Torsten Wolfgang},
title = {{Fluid Sketching — Immersive Sketching Based on Fluid Flow}},
booktitle = {Proceedings of IEEE Virtual Reality Conference 2018},
year = {2018}
}
Vista Widgets: A Framework for Designing 3D User Interfaces from Reusable Interaction Building Blocks
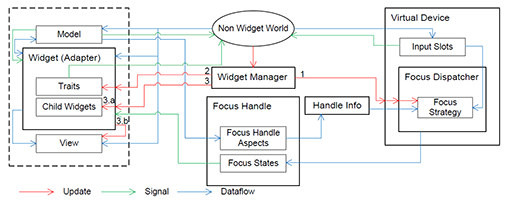
Virtual Reality (VR) has been an active field of research for several decades, with 3D interaction and 3D User Interfaces (UIs) as important sub-disciplines. However, the development of 3D interaction techniques and in particular combining several of them to construct complex and usable 3D UIs remains challenging, especially in a VR context. In addition, there is currently only limited reusable software for implementing such techniques in comparison to traditional 2D UIs. To overcome this issue, we present ViSTA Widgets, a software framework for creating 3D UIs for immersive virtual environments. It extends the ViSTA VR framework by providing functionality to create multi-device, multi-focus-strategy interaction building blocks and means to easily combine them into complex 3D UIs. This is realized by introducing a device abstraction layer along sophisticated focus management and functionality to create novel 3D interaction techniques and 3D widgets. We present the framework and illustrate its effectiveness with code and application examples accompanied by performance evaluations.
@InProceedings{Gebhardt2016,
Title = {{Vista Widgets: A Framework for Designing 3D User Interfaces from Reusable Interaction Building Blocks}},
Author = {Gebhardt, Sascha and Petersen-Krau, Till and Pick, Sebastian and Rausch, Dominik and Nowke, Christian and Knott, Thomas and Schmitz, Patric and Zielasko, Daniel and Hentschel, Bernd and Kuhlen, Torsten W.},
Booktitle = {Proceedings of the 22nd ACM Conference on Virtual Reality Software and Technology},
Year = {2016},
Address = {New York, NY, USA},
Pages = {251--260},
Publisher = {ACM},
Series = {VRST '16},
Acmid = {2993382},
Doi = {10.1145/2993369.2993382},
ISBN = {978-1-4503-4491-3},
Keywords = {3D interaction, 3D user interfaces, framework, multi-device, virtual reality},
Location = {Munich, Germany},
Numpages = {10},
Url = {http://doi.acm.org/10.1145/2993369.2993382}
}
Level-of-Detail Modal Analysis for Real-time Sound Synthesis
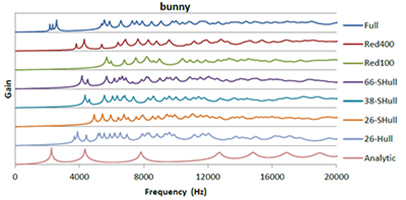
Modal sound synthesis is a promising approach for real-time physically-based sound synthesis. A modal analysis is used to compute characteristic vibration modes from the geometry and material properties of scene objects. These modes allow an efficient sound synthesis at run-time, but the analysis is computationally expensive and thus typically computed in a pre-processing step. In interactive applications, however, objects may be created or modified at run-time. Unless the new shapes are known upfront, the modal data cannot be pre-computed and thus a modal analysis has to be performed at run-time. In this paper, we present a system to compute modal sound data at run-time for interactive applications. We evaluate the computational requirements of the modal analysis to determine the computation time for objects of different complexity. Based on these limits, we propose using different levels-of-detail for the modal analysis, using different geometric approximations that trade speed for accuracy, and evaluate the errors introduced by lower-resolution results. Additionally, we present an asynchronous architecture to distribute and prioritize modal analysis computations.
@inproceedings {vriphys.20151335,
booktitle = {Workshop on Virtual Reality Interaction and Physical Simulation},
editor = {Fabrice Jaillet and Florence Zara and Gabriel Zachmann},
title = {{Level-of-Detail Modal Analysis for Real-time Sound Synthesis}},
author = {Rausch, Dominik and Hentschel, Bernd and Kuhlen, Torsten W.},
year = {2015},
publisher = {The Eurographics Association},
ISBN = {978-3-905674-98-9},
DOI = {10.2312/vriphys.20151335}
pages = {61--70}
}
BlowClick: A Non-Verbal Vocal Input Metaphor for Clicking

In contrast to the wide-spread use of 6-DOF pointing devices, freehand user interfaces in Immersive Virtual Environments (IVE) are non-intrusive. However, for gesture interfaces, the definition of trigger signals is challenging. The use of mechanical devices, dedicated trigger gestures, or speech recognition are often used options, but each comes with its own drawbacks. In this paper, we present an alternative approach, which allows to precisely trigger events with a low latency using microphone input. In contrast to speech recognition, the user only blows into the microphone. The audio signature of such blow events can be recognized quickly and precisely. The results of a user study show that the proposed method allows to successfully complete a standard selection task and performs better than expected against a standard interaction device, the Flystick.
Cirque des Bouteilles: The Art of Blowing on Bottles

Making music by blowing on bottles is fun but challenging. We introduce a novel 3D user interface to play songs on virtual bottles. For this purpose the user blows into a microphone and the stream of air is recreated in the virtual environment and redirected to virtual bottles she is pointing to with her fingers. This is easy to learn and subsequently opens up opportunities for quickly switching between bottles and playing groups of them together to form complex melodies. Furthermore, our interface enables the customization of the virtual environment, by means of moving bottles, changing their type or filling level.
Efficient Modal Sound Synthesis on GPUs
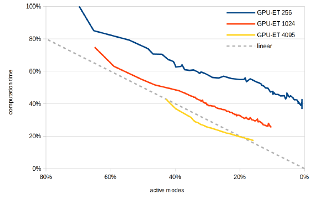
Modal sound synthesis is a useful method to interactively generate sounds for Virtual Environments. Forces acting on objects excite modes, which then have to be accumulated to generate the output sound. Due to the high audio sampling rate, algorithms using the CPU typically can handle only a few actively sounding objects. Additionally, force excitation should be applied at a high sampling rate. We present different algorithms to compute the synthesized sound using a GPU, and compare them to CPU implementations. The GPU algorithms shows a significantly higher performance, and allows many sounding objects simultaneously.
Reorientation in Virtual Environments using Interactive Portals

Real walking is the most natural method of navigation in virtual environments. However, physical space limitations often prevent or complicate its continuous use. Thus, many real walking interfaces, among them redirected walking techniques, depend on a reorientation technique that redirects the user away from physical boundaries when they are reached. However, existing reorientation techniques typically actively interrupt the user, or depend on the application of rotation gain that can lead to simulator sickness. In our approach, the user is reoriented using portals. While one portal is placed automatically to guide the user to a safe position, she controls the target selection and physically walks through the portal herself to perform the reorientation. In a formal user study we show that the method does not cause additional simulator sickness, and participants walk more than with point-and-fly navigation or teleportation, at the expense of longer completion times.
Best Technote!
@INPROCEEDINGS{freitag2014,
author={S. Freitag and D. Rausch and T. Kuhlen},
booktitle={2014 IEEE Symposium on 3D User Interfaces (3DUI)},
title={{Reorientation in Virtual Environments Using Interactive Portals}},
year={2014},
pages={119-122},
doi={10.1109/3DUI.2014.6798852},
month={March},
}
Adaptive Human Motion Prediction using Multiple Model Approaches
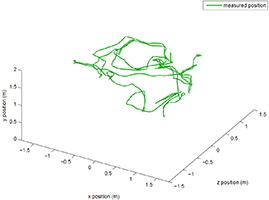
A common problem in Virtual Reality is latency. Especially for head tracking, latency can lead to a lower immersion. Prediction can be used to reduce the effect of latency. However, for good results the prediction process has to be reliably fast and accurate. Human motion is not homogeneous and humans often tend to change the way they move. Prediction models can be designed for these special motion types. To combine the special models, a multiple model approach is presented. It constantly evaluates the quality of the different specialized motion prediction and adjusts the set of motion models. We propose two variants, and compare them to a reference prediction algorithm.
Comparing Auditory and Haptic Feedback for a Virtual Drilling Task

While visual feedback is dominant in Virtual Environments, the use of other modalities like haptics and acoustics can enhance believability, immersion, and interaction performance. Haptic feedback is especially helpful for many interaction tasks like working with medical or precision tools. However, unlike visual and auditory feedback, haptic reproduction is often difficult to achieve due to hardware limitations. This article describes a user study to examine how auditory feedback can be used to substitute haptic feedback when interacting with a vibrating tool. Participants remove some target material with a round-headed drill while avoiding damage to the underlying surface. In the experiment, varying combinations of surface force feedback, vibration feedback, and auditory feedback are used. We describe the design of the user study and present the results, which show that auditory feedback can compensate the lack of haptic feedback.
@inproceedings {EGVE:JVRC12:049-056,
booktitle = {Joint Virtual Reality Conference of ICAT - EGVE - EuroVR},
editor = {Ronan Boulic and Carolina Cruz-Neira and Kiyoshi Kiyokawa and David Roberts},
title = {{Comparing Auditory and Haptic Feedback for a Virtual Drilling Task}},
author = {Rausch, Dominik and Aspöck, Lukas and Knott, Thomas and Pelzer, Sönke and Vorländer, Michael and Kuhlen, Torsten},
year = {2012},
publisher = {The Eurographics Association},
ISSN = {1727-530X},
ISBN = {978-3-905674-40-8},
DOI = {10.2312/EGVE/JVRC12/049-056}
pages= { -- }
}
Visualizing Acoustical Simulation Data in Immersive Virtual Environments

In this contribution, we present an immersive visualization of room acoustical simulation data. In contrast to the commonly employed external viewpoint, our approach places the user inside the visualized data. The main problem with this technique is the occlusion of some data points by others. We present different solutions for this problem that allow an interactive analysis of the simulation data.
Bimanual Haptic Simulator for Medical Training: System Architecture and Performance Measurements
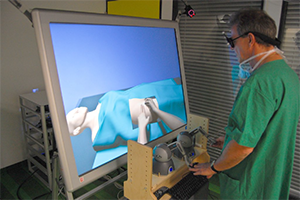
In this paper we present a simulator for two-handed haptic interaction. As an application example, we chose a medical scenario that requires simultaneous interaction with a hand and a needle on a simulated patient. The system combines bimanual haptic interaction with a physics-based soft tissue simulation. To our knowledge the combination of finite element methods for the simulation of deformable objects with haptic rendering is seldom addressed, especially with two haptic devices in a non-trivial scenario. Challenges are to find a balance between real-time constraints and high computational demands for fidelity in simulation and to synchronize data between system components. The system has been successfully implemented and tested on two different hardware platforms: one mobile on a laptop and another stationary on a semi-immersive VR system. These two platforms have been chosen to demonstrate scaleability in terms of fidelity and costs. To compare performance and estimate latency, we measured timings of update loops and logged event-based timings of several components in the software.
@inproceedings {EGVE:JVRC11:039-046,
booktitle = {Joint Virtual Reality Conference of EGVE - EuroVR},
editor = {Sabine Coquillart and Anthony Steed and Greg Welch},
title = {{Bimanual Haptic Simulator for Medical Training: System Architecture and Performance Measurements}},
author = {Ullrich, Sebastian and Rausch, Dominik and Kuhlen, Torsten},
year = {2011},
pages={39--46},
publisher = {The Eurographics Association},
DOI = {10.2312/EGVE/JVRC11/039-046}
}
3D Sketch Recognition for Interaction in Virtual Environments

We present a comprehensive 3D sketch recognition framework for interaction within Virtual Environments that allows to trigger commands by drawing symbols, which are recognized by a multi-level analysis. It proceeds in three steps: The segmentation partitions each input line into meaningful segments, which are then recognized as a primitive shape, and finally analyzed as a whole sketch by a symbol matching step. The whole framework is configurable over well-defined interfaces, utilizing a fuzzy logic algorithm for primitive shape learning and a textual description language to define compound symbols. It allows an individualized interaction approach that can be used without much training and provides a good balance between abstraction and intuition. We show the real-time applicability of our approach by performance measurements.
@inproceedings {PE:vriphys:vriphys10:115-124,
booktitle = {Workshop in Virtual Reality Interactions and Physical Simulation "VRIPHYS" (2010)},
editor = {Kenny Erleben and Jan Bender and Matthias Teschner},
title = {{3D} Sketch Recognition for Interaction in Virtual Environments},
author = {Rausch, Dominik and Assenmacher, Ingo and Kuhlen, Torsten},
year = {2010},
publisher = {The Eurographics Association},
DOI = {10.2312/PE/vriphys/vriphys10/115-124}
}
Virtual Reality System at RWTH Aachen University
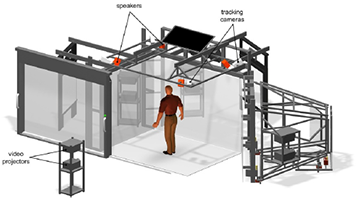
During the last decade, Virtual Reality (VR) systems have progressed from primary laboratory experiments into serious and valuable tools. Thereby, the amount of useful applications has grown in a large scale, covering conventional use, e.g., in science, design, medicine and engineering, as well as more visionary applications such as creating virtual spaces that aim to act real. However, the high capabilities of today’s virtual reality systems are mostly limited to firstclass visual rendering, which directly disqualifies them for immersive applications. For general application, though, VR-systems should feature more than one modality in order to boost its range of applications. The CAVE-like immersive environment that is run at RWTH Aachen University comprises state-of-the-art visualization and auralization with almost no constraints on user interaction. In this article a summary of the concept, the features and the performance of our VR-system is given. The system features a 3D sketching interface that allows controlling the application in a very natural way by simple gestures. The sound rendering engine relies on present-day knowledge of Virtual Acoustics and enables a physically accurate simulation of sound propagation in complex environments, including important wave effects such as sound scattering, airborne sound insulation between rooms and sound diffraction. In spite of this realistic sound field rendering, not only spatially distributed and freely movable sound sources and receivers are supported, but also modifications and manipulations of the environment itself. The auralization concept is founded on pure FIR filtering which is realized by highly parallelized non-uniformly partitioned convolutions. A dynamic crosstalk cancellation system performs the sound reproduction that delivers binaural signals to the user without the need of headphones. The significant computational complexity is handled by distributed computation on PCclusters that drive the simulation in real-time even for huge audio-visual scenarios.
@inproceedings{schroder2010virtual,
title={Virtual reality system at RWTH Aachen University},
author={Schr{\"o}der, Dirk and Wefers, Frank and Pelzer, S{\"o}nke and Rausch, Dominik and Vorl{\"a}nder, Michael and Kuhlen, Torsten},
booktitle={Proceedings of the international symposium on room acoustics (ISRA), Melbourne, Australia},
year={2010}
}
A Sketch-Based Interface for Architectural Modification in Virtual Environments

This paper presents a sketch-based interface for interactive modification of architectural design prototypes inside a virtual environment. The user can move around in the scenery and create line drawings to add annotations. In order to modify or extend the scenery, she can sketch command symbols, which are then recognized by the application to trigger the application defined commands. This allows the user to modify existing objects in the scene as well as to create new ones. This sketch based interface is supposed to act as a front-end application for architects in order to have a tool for the interactive reconfiguration of rooms and interior in a visual-acoustic virtual environment.
@inproceedings{rausch2008sketch,
title={ A Sketch-Based Interface for Architectural Modification in Virtual Environments},
author={Rausch, Dominik and Assenmacher, Ingo},
booktitle={5. Workshop der GI-Fachgruppe VR/AR },
year={2008}
}
